Statistics and Methodology
The Statistics and Methodology division at CTU Bern offers free consultancy services in research design and statistical analysis, supports Central Data Monitoring activities, and performs statistical analyses.
The overarching aim of our consultancy work is to promote the use of appropriate study designs to address the question at hand, as well as methods of data analysis that provide coherent and relevant information while realistically acknowledging the uncertainty in the results. Services include consulting on designing and analyzing clinical trials and observational studies, sample size calculation, contribution to statistical parts of the grant proposal and study protocol, setting-up statistical analysis plans (SAP), performing statistical analysis, preparing statistical reports, and support with manuscript writing.
Team members
Team members

- Name / Titel
- Limacher Andreas, PhD
- Funktion
- Head of Statistics and Methodology
- andreas.limacher@unibe.ch
- Phone
- +41 31 684 35 10

- Name / Titel
- Branca Mattia, PhD
- Funktion
- Senior Statistician
- mattia.branca@unibe.ch
- Phone
- +41 31 684 55 29

- Name / Titel
- Bütikofer Lukas, PhD
- Funktion
- Senior Statistical Consultant
- lukas.buetikofer@unibe.ch
- Phone
- +41 31 684 35 28

- Name / Titel
- Chalkou Konstantina, PhD
- Funktion
- Senior Statistician
- konstantina.chalkou@unibe.ch
- Phone
- +41 31 684 68 62

- Name / Titel
- Haynes Alan, PhD
- Funktion
- Senior Statistician
- alan.haynes@unibe.ch
- Phone
- +41 31 684 59 37

- Name / Titel
- Heg Dik, PD PhD
- Funktion
- Senior Statistical Consultant 'Cardiovascular Health'
- dierik.heg@unibe.ch
- Phone
- +41 31 684 35 56

- Name / Titel
- Helfenstein Fabrice, PhD
- Funktion
- Senior Statistician
- fabrice.helfenstein@unibe.ch
- Phone
- +41 31 684 68 29

- Name / Titel
- Losdat Sylvain, PhD
- Funktion
- Senior Statistician
- sylvain.losdat@unibe.ch
- Phone
- +41 31 684 55 65

- Name / Titel
- Moser André, PhD
- Funktion
- Senior Statistician
- andre.moser@unibe.ch
- Phone
- +41 31 684 35 08

- Name / Titel
- Muresan, Iulia-Maia, MSc
- Funktion
- Statistician
- iulia-maia.muresan@unibe.ch
- Phone
- +41 31 684 68 23

- Name / Titel
- Rossel Jean-Benoît, PhD
- Funktion
- Senior Statistician
- jean-benoit.rossel@unibe.ch
- Phone
- +41 31 684 55 63

- Name / Titel
- Roumet Marie, PhD
- Funktion
- Senior Statistician
- marie.roumet@unibe.ch
- Phone
- +41 31 684 56 74

- Name / Titel
- Stalder Odile, MSc
- Funktion
- Senior Statistician
- odile.stalder@unibe.ch
- Phone
- +41 31 684 33 27
Statistical analysis
Statistical analysis
Statistical staff at CTU Bern has a wide experience in analyzing various study types such as:
- Cohort and case-control studies
- Randomized-controlled trials including cluster-randomized trials
- Diagnostic accuracy and method comparison studies
- Meta-analyses including meta-regression and network meta-analysis
using statistical analyses techniques such as:
- Multivariable regression-based model-building
- Derivation and validation of prediction models and prediction tools
- Machine learning methods, e.g. random forest, regression trees, vector machines
- Multilevel/mixed-effects models
- Multivariate analysis (psychometrics)
- Survival analysis, incl. competing risk and multi state models
- Bayesian statistics
CTU Bern has only limited infrastructure for large-scale data analysis such as analyzing genome-wide association studies.
Workflow
Workflow
Ideally, our statisticians are involved early on in the planning of a clinical study. Although not optimal, we also support investigators after data collection was completed. In any case successful work means that there is a close collaboration.
The ideal statistical workflow for a clinical study would lead through the following steps:
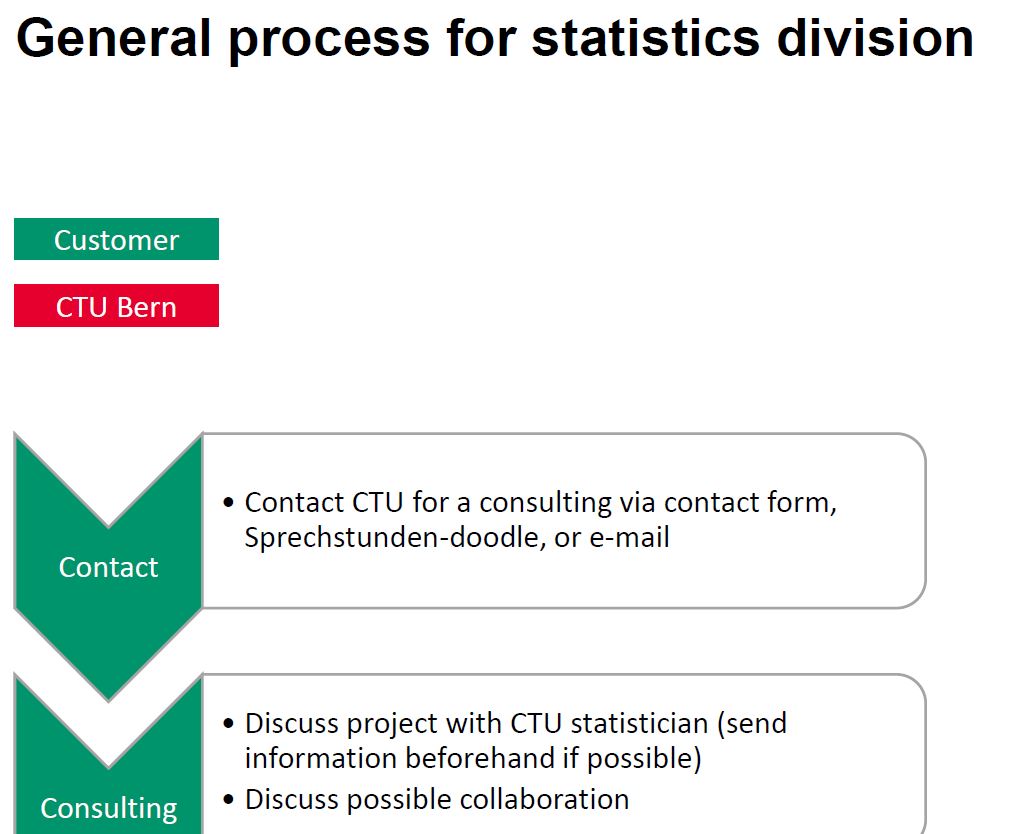
Consulting
Aim: to fix the study objectives, identify the appropriate study design for the objectives, define outcomes of interest and study flow, address the key methodological issues, define appropriate statistical methods, and to provide sample-size estimates
Offer
Aim: to provide a cost estimate for the statistical analysis based on the available information
Grant proposal / study protocol
Aim: to review and/or write the section on statistical analysis in the grand proposal and/or study protocol and to provide feedback on other parts of the document with respect to methodological issues
Statistical Analysis Plan
Aim: to fix all details of the statistical analysis. The Statistical Analysis Plan will be signed by the statistician and the Sponsor.
Central Data Monitoring
Aim: to regularly monitor the accumulating data in collaboration with the Quality Assurance and Monitoring division.
Data preparation and validation
Aim: to prepare the dataset(s) for the analysis as defined in the Statistical Analysis Plan and validate the data. If the study database was not provided by CTU Bern please follow the specifications as described below.
Data analysis
Aim: to analyze the study data and prepare a report as defined in the Statistical Analysis Plan.
Publication
Aim: to define display items (tables and figures) based on the planned publications and to write-up/provide feedback on the methods section, results and discussion of any manuscript resulting from the data analysis
Guidelines for supplied datasets
Guidelines for supplied datasets
If you want us to analyze a dataset from your own database the following should be read carefully. Not taking this advice into account may create substantial additional preparatory work.
Statistical analysis software (Stata, R, SAS, SPSS, etc.) is based on a uniform, rectangular data structure: the lines represent the cases (e.g., patients) and the columns represent the variables e.g. identification number, sex, age, hemoglobin level. Such a file contains only one line per case (wide format). In this format, multiple measurements of a variable over time (e.g. the developing of laboratory values) must be characterized by several variables (e.g., BLOOD1, BLOOD2, etc.).
Personal data has to be de-identified before sending it to us (no names or initials, no PID, no exact date of birth but only birth-year etc.). Datasets containing identifying data will be rejected.
In order to process data with the software existing at CTU Bern, certain conditions have to be met.
- Avoid data collection in Excel because there is no audit trail nor access control as required by the human research act (HFG). Rather use a proper database like REDCap. If nevertheless done, the guidance below should be followed.
- Stata data files can be input directly. A labelled dataset is preferred. If not available, a data dictionary with explanation of the dataset is required.
- ASCII files e.g. .txt- and .csv-files require special precautionary measures concerning the separator and the coding of missing values. Their use should be limited to cases for which other ways of conversion do not exist.
- Data-files from other statistical software such R, SAS or SPSS may also be possible but need to be checked carefully beforehand.
- Under no circumstances should data be input in word processing software.
Excel files
Statisticians may spend hours transferring Excel tables to files readable by statistical software. This time can be better used for analysis and interpretation. Hence, please consider:
- Choose a simple table structure that can be easily exported/imported.
- One variable per column.
- One patient per line, also for multiple measurements.
Variables
- The first line contains the variable names.
- Name the variables according to Stata convention: start with a letter, no special characters or spaces (letters, numbers, underscores "_" are allowed), no longer than 32 characters.
- The variable name should reflect the content of the variable.
- For multiple measurements: Use names such as hb1-hb10.
- Do not allocate a variable name twice.
- Variables/columns must be uniformly formatted and include uniform entries (i.e., only numbers, only dates (formatted as 03.04.97 or 03.04.1997) or only text).
Data
- De-identify data by changing names to numbers.
- Avoid special characters (use also only sparingly in text columns and only if unavoidable). In particular, do not use semicolons (as they are interpreted as separators)!
- Leave cells with missing data completely empty.
- If calculations have been done in Excel: Input the results as numerical values instead of as formulas, which are recalculated each time the table is opened (1. Copy; 2. Paste special; 3. Paste-Values). Delete all columns containing results that were computed from other columns.
- One value per field only; do not overlay a field with a second value (this is possible in Excel but creates additional observations when transferred to Stata).
- Complete all columns (as far as data are present). Do not enter "no" in fields remaining empty, "no" cannot be differentiated from missing values ("data not collected").
General
- Colors and descriptive statistics (e.g., mean, median, frequencies) cannot be exported. Transfer your color-coding to a (numerical) code with numbers in a dedicated variable.
- Avoid comments between the values (e.g., cause of death next to date of death). Create instead a separate column (as last column) for comments/characteristics.
- Procedure for several groups e.g. from a randomized-controlled trial: Create a single table with only one column in which the group affiliation is documented (do not create one table per group).
- Avoid section headers (e.g., admission, discharge) under which the same variable names are allocated.